
为了应对面试官的拷打,写下此文,方便我复习这个数据库的实现方法。
Project 1
Task 1
这一部分主要是要求实现一个LRU-K的替换算法。
LRU是最近最少使用算法,也就是把buffer里面,上次使用时间距离现在最远的元素换出去。但是LRU的问题在于,如果有很多“偶发性”数据访问,即只访问一两次的数据,那么LRU会替换掉几乎所有元素,从而降低命中率。
LRU-K的想法是,访问过K次及以上的数据和其他数据分开来算。显然,前者是更需要放在缓存里的,而后者是“偶发性”数据。
这里同样定义了距离,当访问次数大于等于\(K\)时,该元素的距离为当前时间点减去之前的第\(K\)次访问的时间点。如果一个元素的访问次数不足\(K\),则距离无限大。换出的规则仍然是,把距离最大的元素换出。如果有多个元素距离无限大,则把最近访问最远的那个元素换出。相当于对它们进行朴素的LRU。
下面具体解析一下在src/include/buffer/lru_k_replacer.h里面的东西的作用
LRUNode:这里记录我们刚刚提到的元素的信息。其中:history_记录了最近的至多\(K\)次访问的时间戳,表头为最远的,表尾为最近的。k_代表累计有几次访问,最大等于LRU-K算法设定的\(K\)值,不能超过。fid_代表在buffer pool中的帧号,其作用在于通过帧号找到页号,具体会用在buffer pool中。is_evictable_,为真时代表此元素可以换出。
LRUKReplacer:这个就是具体实现LRU-K的地方。- 先看看它的成员变量:
node_store_,用于存储帧号对应的LRUNode。current_timestamp_用于记录现在的时间戳,不需要用unix时间戳什么的,我们只要每次访问后将其加一即可。curr_size_指的是目前有多少个evictable的帧。replacer_size_指LRU-K能容纳多少Nodek_即代表LRU-K中的\(K\)值。latch_即我们使用的互斥锁。
- 再来看看成员函数:
- 构造析构略
Evict指换出一个帧,参数为换出的帧其帧号的指针,返回真时换出成功,否则换出失败。换出规则即之前介绍的规则。RecordAccess记录给定帧的一次访问。每次访问都要增加current_timestamp_,如果不在node_store_中还需要新建。然后修改frame_id对应的node的数据,包括k_和history_。如果已经有\(K\)次访问了,还需要注意不要自增超过\(K\),以及history_不要多于\(K\)个记录。SetEvictable即修改给定帧的可换出属性,同时会影响curr_size_的值。Remove即删除给定帧的访问记录。注意只有evictable的帧才能换出。同时会影响curr_size_的值。
- 先看看它的成员变量:
这里面所有的frame_id的范围都在[0,replacer_size_)中,否则为非法访问。
Task 2
这里要求实现一个磁盘调度算法。不过这个算法并不高深,就是一个简单的FIFO,使用一个并发安全的队列实现。
src/include/storage/disk/disk_scheduler.h中,有:
DiskRequest:代表一次磁盘访问的属性,包括is_write_即是读还是写data_一个指针。读磁盘时,指向要读入的内存数组的开头。写磁盘时,指向要写入的内存数组的开头。大小是固定的,为Page的大小,在bustub中为4096,不足的都会补0page_id_即写入磁盘的第几页。在后面会详细介绍,我们只用知道bustub的xxx.db文件是一页一页顺着排列的就行。页号从0开始。callback_一个线程同步的变量,后面(task 3)介绍。
DiskScheduler:即实现磁盘调度算法的部分- 其成员变量有:
disk_manager_磁盘调度算法要向其发送磁盘操作请求,之后介绍request_queue_即FIFO算法所用到的队列background_thread_即在后台不断把队列里的请求拿出来,发送给disk_manager的线程
- 其成员函数有:
- 构造函数,在构造的时候,就启动了
background_thread_线程,其执行StartWorkerThread Schedule,即简单地把一个DiskRequest放入队列中StartWorkerThread,可以看作是生产者-消费者模型中的消费者。其不断地从队列中拿出请求,向disk_manager_发送对应请求,然后将callback_赋值。无限循环直到拿出的请求是一个std::nullopt(队列中存的是std::optional<DiskRequest>)- 析构函数,主要负责向队列中放入
nullopt,让其停止。然后和后台的线程进行join
- 构造函数,在构造的时候,就启动了
- 其成员变量有:
这个队列在这个项目里是已经提供好了的,不需要自己实现。不过为了防止被面试官拷打,我们来解析一下这个队列的实现方式。其被称作Channel,在src/include/common/channel.h。其底层是STL的queue,在此基础上加入了一个互斥锁和一个条件变量。只支持两个方法,即Put在队尾放入元素,Get取出队头元素(相当于front和pop二合一)。实现也非常经典,值得抄下来学习
void Put(T element){
std::unique_lock<std::mutex> lk(m_);
q_.push(std::move(element));
lk.unlock();
cv_.notify_all();
}
T Get(){
std::unique_lock<std::mutex> lk(m_);
cv_.wait(lk, [&](){return !q_.empty()})
T element = std::move(q_.front());
q_.pop();
return element;
}
然后我们来看看DiskManager具体怎么访问硬盘的。抛去一些不重要的,有这些成员变量:
db_io_,它是一个std::fstream,至此真相大白,根本没有什么更底层的东西,只是一个STL自带的文件流而已。file_name_,数据库文件的名字。db_io_latch_,在硬盘读写的时候持有锁,防止冲突。
再来看看其中比较重要的几个成员函数:
- 构造函数,传入文件名,打开fstream。
WritePage,传入页号,以及data的指针。前面也提到过,bustub的数据文件就是把页顺序排列,我们知道页号、知道页大小,就知道页的开头在文件中的位置。这里需要使用fstream的seekp先定位,然后再write写出数据。ReadPage,传入页号,以及data的指针。基本上同上。只是需要注意,如果文件的最后一页不足4096,那么需要在内存中把后面全部填充0
Task 3
这里就是真正实现buffer pool的地方。buffer pool对于数据库的作用,类似于cache对于cpu的作用。cpu一般是先把内存中的东西放到cache中,然后之后读取就会更快了。基于空间局部性和时间局部性,虽然cache比内存小,但是也可以提升访问速度。而buffer pool所做的,就是把磁盘中的东西拿到内存。
buffer pool中的东西分为两部分,第一部分是Project 1中实现的,其只实现了基本的操作。而Project 2中实现的下半部分主要是负责更好的自动控制,不再需要手动进行Unpin等操作,解放程序员。
还是先介绍BufferPoolManager(src/include/buffer/buffer_pool_manager.h)中的成员变量:
pool_size_,代表这个buffer pool中能容纳多少个page。LRUKReplacer的大小将会和它一致next_page_id_,其为一个std::atomic<page_id_t>,也就是说可以并发地访问。其中page_id_t在这里定义为了uint32_t。之后创建一个新页的时候需要用到这个值。pages_,一个数组,用于存放所有page的disk_scheduler_,即task 2实现的东西page_table_,通过页号找到帧号replacer_,即我们的LRU-K算法free_list_,其最初的大小等于pool_size_,存储了所有空闲的帧的帧号latch_,自己的互斥量。
成员函数:
- 构造函数,主要就是传入大小、\(K\)值,
DiskManager等。这里要初始化pages_ = new Page[pool_size_],初始化replacer_,同时把所有帧号放到free_list_里 - 析构函数,主要进行
delete[] pages_ NewPage,分配一个新页,返回这个新页的指针,新页的页号通过参数中的指针返回。由于我们是在内存中分配新页的,所以要先找一个位置,如果有空闲的帧就直接获取一个帧号,否则换出一个帧到硬盘上(即判断是否为脏页,为脏则要向DiskManager发出一个写请求,然后从page_table_中删掉这一项。否则直接从page_table_中删掉。这里删除的时候,需要auto future = r.callback_.get_future(),然后再发送请求,然后future.wait(),这样在删除完成之前就会被阻隔,从而线程同步。),然后继续使用这个换出的帧号。在pages_数组上,直接对这个元素进行初始化。例如重置数据、分配页号、设置脏位、设置pin_count_。然后写入page_table_,并在replacer_中记录一次访问,以及设定evictable为false。这里可能所有页面都被设置为不能换出,这里要返回nullptrFetchPage,根据页号获取一个页。这个页可能已经在buffer pool里了,那么直接读这个页。否则,要去硬盘里找。同前,有空闲帧就分配、否则换出,等等操作。在之后,我们要给这个page的pin_count_加一,表明又有一个新的线程在访问这个页。以及,同样地更新page_table_、replacer_等。UnpinPage,一个线程不再需要这个页时,需要将其unpin,也就意味着对应的pin_count_减一。同时UnpinPage的参数里会带有is_dirty,用于标注这个页的脏位。注意,如果页不在buffer pool里,或者pin_count_已经归零,就不需要进行操作了。页的这些元信息只存在于内存中,硬盘中只有data,所以pin_count_不需要从硬盘里拿出来减一。如果成功进行了减一,并且计数器归零,就可以在replacer_中把evictable设置为true了FlushPage,给定页号,无论是否为脏页,都写回硬盘中。之后设置为非脏页。其他信息不做改动。FlushAllPages,刷新所有页。DeletePage,这里说的不是删掉硬盘上的页。是删掉buffer pool中的页,并标记为空闲帧。当然,如果给出的页号本来就不在buffer pool里,则什么改动都不做。删除的时候已经假定引用计数归零了,所以如果非零,则是非法操作。需要从page_table_、replacer_中删掉相应的元素。然后插入到free_list_中,把原来pages_这个位置上的页元信息重置。AllocatePage,其实就是分配了一个新页号return next_page_id_++DeallocatePage,这就是个空函数,bustub里根本不考虑这个。
之后我们来关注一下这个Page里面都有什么东西,在src/include/storage/page/page.h中,成员变量:
data_,一个指针,和读写硬盘的那个data指针类似,就是指向一个数组的头。大小固定为4096,即页大小。在构造函数中分配内存。析构中释放。page_id_,页号。pin_count_,表示有多少线程正在使用这个页。is_dirty_,脏位。rwlatch_,读写锁。实际上是用std::shared_mutex实现的,写的时候进行lock()和unlock(),读的时候进行lock_shared()和unlock_shared()。
成员函数可说的反而不多,除了一大堆getter和setter、读写上锁之外,有:
ResetMemory,就是一个memset,把data_的内容初始化。
这里面还有两个叫GetLSN和SetLSN的函数,不知道干嘛的,整个项目里倒也没用过这两个函数。
Project 2
Task 1
在上一部分,我们实现的BufferPoolManager实现的比较底层的操作。程序员需要手动创建页、获取页、删除页、Unpin页。本部分要求我们,实现一个wrapper,能够在构造的时候获取页,析构的时候Unpin、删除页。同时,实现要求我们保证并发安全,我们也要自动地控制锁。
首先关注src/include/storage/page/page_guard.h,其中有三个类:
BasicPageGuardReadPageGuardWritePageGuard
这三个类都是独占资源的类,所以类似于unique_ptr,它们的拷贝构造和拷贝赋值被禁用了。看看它们的成员变量:
BasicPageGuardbpm_指向一个BufferPoolManager的指针page_指向自己所管理的页的指针is_dirty_脏位
ReadPageGuardguard_是一个BasicPageGuard。本类的成员函数的实现方式,使得本页只读,后面介绍。
WritePageGuardguard_是一个BasicPageGuard。本类的成员函数的实现方式,使得本页可读写,后面介绍。
看看它们的前几个成员函数:
BasicPageGuard- 默认构造函数,其传入
bpm和page指针来初始化。 - 移动构造函数,把另外一个guard的
page_,is_dirty_,bpm_全部都移动过来,之前的清空。 Drop,即废弃掉这个页,或者说放弃控制权。这里就需要调用bpm_中的UnpinPage了,传入自己的页号和脏位。之后再把成员变量清空。- 移动赋值函数,和移动构造类似,但是要先把自己的资源
Drop掉,再去考虑移动的事。 - 析构函数,可以直接调用
Drop
- 默认构造函数,其传入
ReadPageGuard- 默认构造函数,传入的也是
bpm和page指针,其用来初始化guard_成员。其实我不是很明白这里为什么没有上读者锁(项目原版的代码),可能是因为项目里根本没有地方直接构造ReadPageGuard吧。 - 移动构造函数,我们只用移动
guard_即可。虽然我写了先把that解锁再把this加锁,但我想了一下好像没有必要,甚至可能是错的。不过评测没有问题。 Drop,废弃页。注意如果this已经有一个页,需要先解锁,然后再Unpin。之后再把guard_的信息清空。如果弄反了,可能Unpin后页立刻换出,然后我们再解锁,解锁的就是其他页的锁了。- 移动赋值函数,同前,如果需要,先考虑
Drop掉自己。 - 析构函数,调用
Drop
- 默认构造函数,传入的也是
WritePageGuard,和ReadPageGuard基本一样,只不过加锁的时候加的是写者锁。
前面也提到,一般不会直接调用ReadPageGuard和WritePageGuard的默认构造函数,我们会通过BasicPageGuard中内置的两个函数来“升级”成另外两个:
UpgradeRead,首先给page_上读者锁,然后记录下page_和bpm_的指针,清空自己的成员变量,调用默认构造函数返回一个ReadPageGuardUpgradeWrite,同上,只不过上的是写者锁。
这三个类还有几个读取数据的成员函数
BasicPageGuardPageId,获取page_的页号GetData,获取page_的data_指针,一个const char *,也即不可修改内容As,将GetData中获得的指针转化为另一个类型的指针,即const T *GetDataMut,同GetData,只不过将is_dirty_设置为true,返回char *AsMut,将GetDataMut获得的指针转为T *
ReadPageGuard,只包含PageId,GetData,AsWritePageGuard,包含全部五个函数。
之后我们回到src/include/buffer/buffer_pool_manager.h中,解决上个Project的遗留问题
FetchPageBasic,首先调用自己的FetchPage获取页号,然后调用BasicPageGuard的默认构造函数构造,然后返回FetchPageRead,调用FetchPageBasic后进行UpgradeRead,返回FetchPageWrite,类似于上条。NewPageGuarded,类似于第一条,使用NewPage的页号。
Task 2
从这里开始要求我们实现一个可扩哈希。我们先把可扩哈希的原理说明一下,从一张图开始
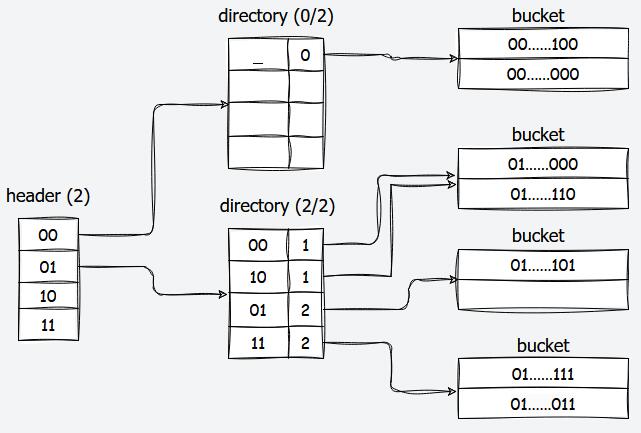
首先可以看到,它是一个三层结构。第一层是header,其大小固定。第二层是directory,其大小可以变化,从只有一项,到大小上限。而第三层是bucket。
header的每一项指向了一个directory(当然如果没有数据的话就指向空指针),而directory的每一项指向了一个bucket,数据实际上是存在bucket里。所以,如果我们要读写一个数据,我们要经过以下步骤:
- 找到该数据对应与
header中的哪一项。 - 从
header的这一项中找到其对应的directory,然后在找到该数据对应该directory中的哪一项 - 从
directory中的这一项找到其对应的bucket,然后在bucket中遍历(bucket可以看做是固定大小的数组),找到所需的数据位置。
具体是根据什么方法来找的呢?
首先,我们会获得该数据的哈希值。假设我们这里得到的哈希值是一个32位无符号整数,那么,根据header的max_depth,提取出哈希值的高max_depth位。如上图,其max_depth为\(2\)。如果我们的哈希值是01...111,那么就要映射到header中的第1项(从0开始计数)。如果是10...111就映射到第2项,以此类推。
接下来,我们在对应的directory里,根据其global_depth,找到哈希值的低global_depth位。例如在global_depth为\(2\)时,01...111就映射到directory的第3项。
可扩哈希具体指的是哪里可扩呢?实际上指的是directory可扩。我们画个简单的情况来介绍:
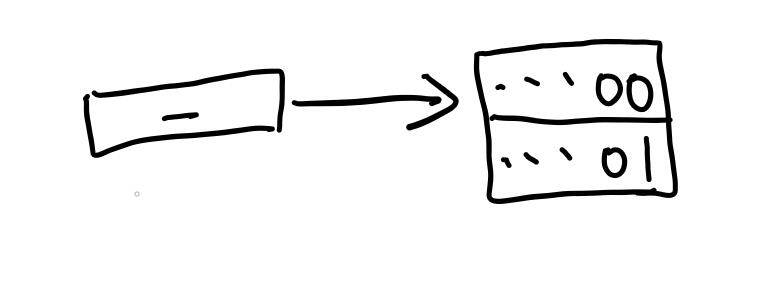
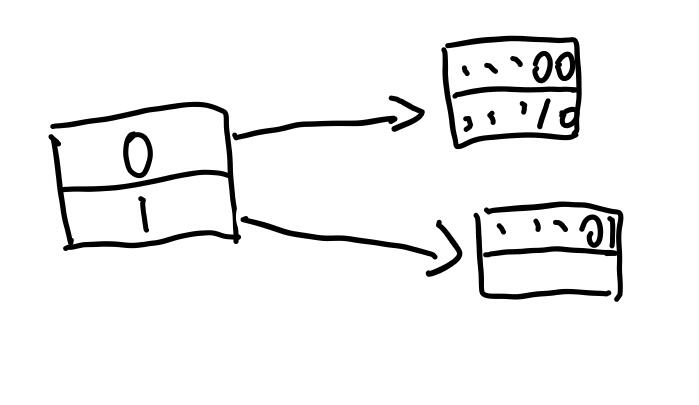
如图,我们省去了header,并且现在directory的global_depth的大小为0,也就是只有第0项。我们这里假设bucket大小为\(2\)。这里我们有一个放了两个数据的bucket,这里用哈希值表示数据。
整个directory有一个global_depth,主要是代表项数,也用来找哈希值对应的bucket。而每一项,有一个local_depth,代表的是,该项指向的bucket中,保证所有数据的哈希值最低的local_depth位是相同的。上图中,local_depth为0,即没有一位是保证相同的。
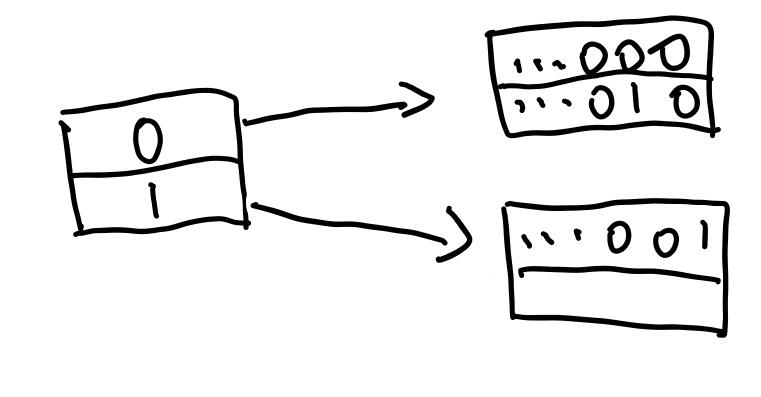
如果我们要再插入一个数据(假设是...10)到其中,怎么做呢?这里显然已经插入满了,所以我们要扩容。首先,把global_depth加一,同时directory的大小也就增加了(大小为\(1<<{global\_depth}\)),所以我们要增加directory的项数,其还是指向这个bucket。
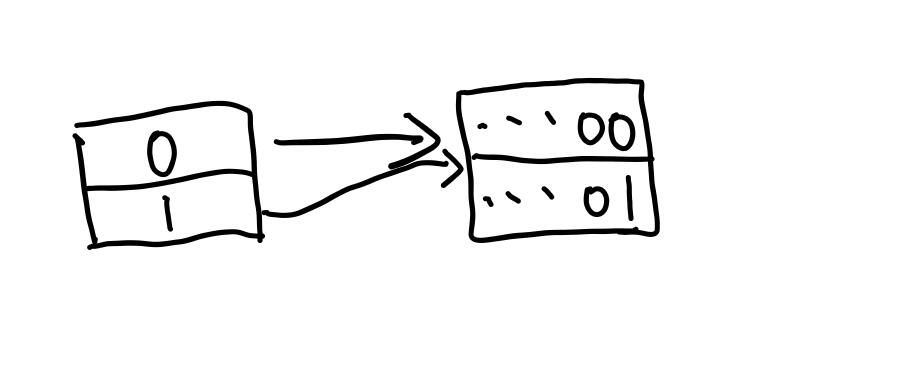
现在,directory的global_depth是1,而两项的local_depth都是0。观察我们要插入的数据...10,其最低1位是0,所以要插入第0项。而第0项指向的bucket仍然是满的。所以我们现在要把bucket分裂。如下:
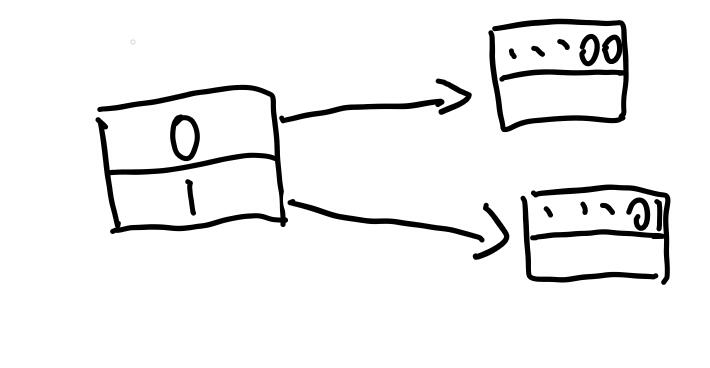
这里分裂的时候,需要按照directory的映射关系,将bucket的数据分别放到相应的新bucket中。这里,我们就可以增加local_depth了,都是1。然后我们再插入数据...10,就可以正常插入了。
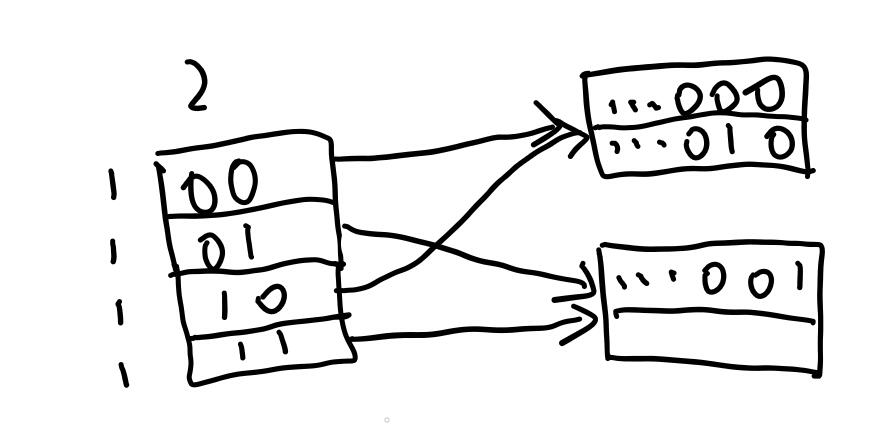
再例如下图
我们插入...100,和之前一样,我们需要先扩容directory
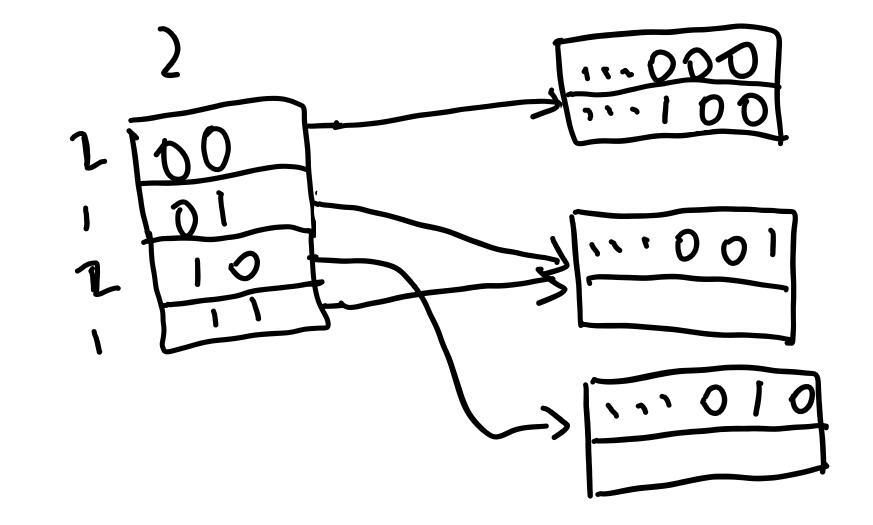
这里global_depth变成了2,写在了上方。而local_depth都是1,写在左边。然后我们的数据...100是映射到第0项,其bucket是满的,所以要分裂bucket,再插入,如下
目前为止,插入和查询就说明白了。删除数据放到之后再说,先来看看代码,首先是src/include/storage/page/extendible_htable_header_page.h
首先,源代码注释中给出了这个page的布局
/**
* Header page format:
* ---------------------------------------------------
* | DirectoryPageIds(2048) | MaxDepth (4) | Free(2044)
* ---------------------------------------------------
*/
这里我们也可以知道,无论是header、directory还是bucket,都是作为一个页存在硬盘上的。大小都依然是4096。
这段注释指出,header存储的数据有两个,一个是MaxDepth,一个是表项。通过阅读后面的代码可知,这个类有两个成员变量。
page_id_t directory_page_ids_[HTABLE_HEADER_ARRAY_SIZE];
uint32_t max_depth_;
表项是用一个数组来表示的,其类型为page_id_t,被using page_id_t = uint32_t定义。而另一个就是代表表的最大大小。因为uint32_t是4字节的,而DirectoryPageIds占2048字节,所以最多有512项。这里也说明,实现上表项不是一个指向directory的指针,而是存储了对应的页号,找到directory需要读取硬盘上的另一个页。
接下来我们看看其中定义的三个静态变量
static constexpr uint64_t HTABLE_HEADER_PAGE_METADATA_SIZE = sizeof(uint32_t);
static constexpr uint64_t HTABLE_HEADER_MAX_DEPTH = 9;
static constexpr uint64_t HTABLE_HEADER_ARRAY_SIZE = 1 << HTABLE_HEADER_MAX_DEPTH;
第一个定义了元信息的大小,第二个定义了bustub默认的max_depth,第三个定义了默认的表大小。接下来我们看ExtendibleHTableHeaderPage的成员函数
- 所有构造函数和析构函数都被禁用了,根据代码的注释说这样是为了保证内存安全。我水平不够暂时不了解原理。
Init,传入max_depth,让我们对header进行初始化。我们照做即可,注意表项要全部初始化为INVALID_PAGE_ID,代表没有指向任何一个directoryHashToDirectoryIndex,传入32位无符号整数的哈希值,找到对应的表项。就像我们之前说的一样,找到高max_depth位就行。return hash>>(32-max_depth_);。可能要特殊处理0深度的情况。GetDirectoryPageId,传入表项下标,返回页号。说白了就是根据数组下标返回数组元素。SetDirectoryPageId,说白了就是根据数组下标设置元素。MaxSize,返回表大小。
之后,我们来看src/include/storage/page/extendible_htable_directory_page.h,首先同样是看page的布局
/**
* Directory page format:
* --------------------------------------------------------------------------------------
* | MaxDepth (4) | GlobalDepth (4) | LocalDepths (512) | BucketPageIds(2048) | Free(1528)
* --------------------------------------------------------------------------------------
*/
存储了四种数据,首先是max_depth_,代表global_depth_的上限,然后就是global_depth_自己,用于表示directory现在的大小,以及用于映射关系。之后是local_depths_,这是一个数组,每个元素都是8位无符号整数,代表对应表项的local_depth,可知最多有512个表项。最后的bucket_page_ids_也是一个数组,类型为page_id_t的数组,存储表项对应的bucket的页号。
static constexpr uint64_t HTABLE_DIRECTORY_MAX_DEPTH = 9;
static constexpr uint64_t HTABLE_DIRECTORY_ARRAY_SIZE = 1 << HTABLE_DIRECTORY_MAX_DEPTH;
静态变量和之前相似。接下来我们看看成员函数
- 所有构造函数和析构函数都被禁用
Init,传入max_depth,初始化max_depth_,global_depth,以及各个表项的信息。HashToBucketIndex,传入32位无符号哈希值,算出对应第几个表项。从前面的讨论可以得到,取hash % (1<<global_depth_)即可。GetSplitImageIndex,传入下标,获得其镜像bucket的下标。这里的镜像bucket指的是,前面进行directory扩容时,表项会翻倍,指向同一个bucket的表项数也会翻倍。每一个旧表项都会有一个新表项与它指向同一个bucket。这两个表项互为镜像。该项的local_depth已知,则当local_depth为零时,镜像为自己。否则镜像下标为bucket_idx ^ (1<<(local_depth-1))。无非是翻转一个二进制位。IncrGlobalDepth,我这里把扩容操作一起做进来了。具体来说,假设原来的大小是sz,那么,global_depth_++之后,新的大小变为sz*2。其中的表项有element[sz+i]=element[i],顺着复制表项即可。DecrGlobalDepth,这里只需要global_depth_--。因为具体的缩容操作更复杂,需要在bucket层面才能执行。这里不需要清空数组多余的部分。CanShrink,具体怎么缩容后面再说。这里只要记住,所有的local_depth都小于global_depth,则可以缩容。
省略掉了一些简单的getter和setter。
之后,我们来看src/include/storage/page/extendible_htable_bucket_page.h,首先同样是看page的布局
/**
* Bucket page format:
* ----------------------------------------------------------------------------
* | METADATA | KEY(1) + VALUE(1) | KEY(2) + VALUE(2) | ... | KEY(n) + VALUE(n)
* ----------------------------------------------------------------------------
*
* Metadata format (size in byte, 8 bytes in total):
* --------------------------------
* | CurrentSize (4) | MaxSize (4)
* --------------------------------
*/
首先是METADATA,八个字节组成,分别是bucket的当前大小和最大大小。之后就是实际存储的键值对(KV)。每个键值对的键和值的大小不定(括号后面的是序号),具体存的什么数据,之后会介绍。
直接来看成员函数
- 所有构造函数和析构函数都被禁用
Init,负责初始化max_size_和size_LookUp,传入key和比较key的比较函数,查找这个bucket里有没有key相等的元素,返回value。(本课程不考虑key冲突,也不考虑multimap这样的情况)Insert,传入key, value, cmp,插入到bucket中,只要key没出现过并且空间还有空闲就可以插入。Remove,传入key, cmp,删除key对应的元素。注意,删除的时候,要把后面的所有元素往前移动一个来填补空缺。因为我们的插入是顺着插入,找到第一个空闲就插入。
省略掉其他的getter和setter,现在我们来讨论一下,它bucket里面的KV究竟是在存什么。
在extendible_htable_bucket_page.cpp中,代码末尾有:
template class ExtendibleHTableBucketPage<int, int, IntComparator>;
template class ExtendibleHTableBucketPage<GenericKey<4>, RID, GenericComparator<4>>;
template class ExtendibleHTableBucketPage<GenericKey<8>, RID, GenericComparator<8>>;
template class ExtendibleHTableBucketPage<GenericKey<16>, RID, GenericComparator<16>>;
template class ExtendibleHTableBucketPage<GenericKey<32>, RID, GenericComparator<32>>;
template class ExtendibleHTableBucketPage<GenericKey<64>, RID, GenericComparator<64>>;
这样的模板特化。首先我们知道了,KV中的V是RID(第一个除外,应该只是用来调试的)。什么是RID?实际上,又可以看做是一种指针。RID存储了两个成员变量page_id_和slot_num_,也就是说,具体的数据是存在别的页中,存在序号为slot_num_的部分。这一部分具体可以阅读src/include/common/rid.h
然后是前面的GenericKey<>是什么?他其实是一个包装的数组,当作哈希值来使用。这个数组里面可以存我们数据库里的具体的数据(称作Tuple,以后再说),也可以直接存整数值(仅用于测试意义)。GenericKey<4>代表数组长度为4(数组类型为char[])。具体可见src/include/storage/index/generic_key.h。
同样的这个文件里,定义了GenericComparator<>,具体做的事就是比较GenericKey<>之间的大小关系,当然,也就是通过比较数组,或者说比较Tuple来实现的。