
简称表
| 简称 | 含义 |
|---|---|
| CPU | 中央处理器 |
| PC | 程序计数器 |
| IR | 指令寄存器 |
| CU | 控制单元 |
| ALU | 算术逻辑单元 |
| ACC | 累加器 |
| MQ | 乘商寄存器 |
| X | 操作数寄存器 |
| MAR | 存储器地址寄存器 |
| MDR | 存储器数据寄存器 |
| MM | 主寄存器 |
| I/O | 输入输出设备 |
| 简称 | 含义 |
|---|---|
| SATA | 串行ATA总线 |
| PCI | 外围设备互联 |
| DMA | 直接存储器访问 |
| DMI | 直接媒体接口 |
| QPI | 快速通道互联 |
| FSB | 前端总线 |
| PCH | 平台控制中心 |
| IOH | 输入/输出中心 |
| ICH | 控制器集线器 |
| MCH | 内存控制器集线器 |
| NVRAM | 非易失型随机存储器 |
| SCSI | 小型计算机系统接口 |
| 简称 | 含义 |
|---|---|
| RAM | 随机存储器 |
| ROM | 只读存储器 |
| SRAM | 静态随机读写存储器 |
| DRAM | 动态随机读写存储器 |
| DDR SDRAM | 双倍数据率同步DRAM |
| MROM | 掩模ROM |
| PROM | 可一次编程ROM |
| EPROM | 可擦除的PROM |
| EEPROM | 电可擦除的EPROM |
| EAROM | 电改写ROM |
| SIMM | 单列直插式存储器模块 |
| DIMM | 双列直插式存储器模块 |
| FIFO | 先进先出算法 |
| LRU | 近期最少使用算法 |
| TLB | 转换后援缓冲器,快表 |
计算机的性能描述
机器字长
指CPU一次能处理的数据位数
存储容量
存储容量=存储单元个数×存储字长。其中MAR反应存储单元个数,MDR反应存储字长。
运行速度
主频/时钟周期
主频与时钟周期二者互为倒数
CPI
执行一条指令(平均)需要的时钟周期数
\[CPI = \dfrac{\text{所有指令的时钟周期之和}}{\text{指令总数}}\\ = \sum(\text{各类指令的CPI}\times \text{该类指令的比例}) \]
MIPS
每秒钟CPU能执行的指令总条数(百万条/秒)
\[MIPS = \dfrac{\text{指令条数}}{\text{执行时间}\times 10^6} \]
\[= \dfrac{\text{指令条数}}{\left(\dfrac{\text{所有指令CPU时钟周期数之和}}{f}\right)\times 10^6}\\ \]
\[= \dfrac{f}{\text{CPI}\times 10^6} \]
其中最后一个公式又称为全性能公式
Amdahl定律
加速比
\[\text{加速比} = \dfrac{\text{改进后的系统性能}}{\text{改进前的系统性能}}\\ \]
\[= \dfrac{\text{改进前的系统执行时间}}{\text{改进后的系统执行时间}} \]
可改进比例\(f_e\)
可改进部分在原系统执行时间中所占的比例
部件加速比\(r_e\)
可改进部分改进后性能提高的程度
Amdahl定律
假设改进前的系统执行时间为\(T_0\),改进后的系统执行时间为\(T_n\),则
\[T_n = T_0\bigg(1-f_e+\dfrac{f_e}{r_e}\bigg) \]
若加速比用\(S_p\)表示,则有
\[S_p = \dfrac{1}{1-f_e+\dfrac{f_e}{r_e}} \]
有多个部件同时可以改进时
\[S_p = \dfrac{1}{(1-\sum f_e)+\sum(\dfrac{f_e}{r_e})} \]
总线和IO
分类
- 按照总线的传输方式不同(定时),可以分为同步总线和异步总线;
- 按照总线中数据线的多少不同(传送信息),可以分为并行总线和串行总线。
- 按照总线的使用方式不同,可以分为专用总线和公用总线。
- 按照连接部件不同,可分为片内总线、系统总线、通信总线
- 按照系统总线传输信息的不同,又可分为数据总线、地址总线、控制总线
总线带宽
\[\text{总线带宽} = \text{数据线宽度}\times \text{总线频率} \]
总线结构
可以分为单总线和多总线结构。
总线控制
中断
存储系统
主存
技术指标
存储容量
\[\text{存储容量}=\text{存储单元个数}\times\text{存储字长} \]
上式的单位是位,如果用字节需要除以8。
存储器带宽
\[B_m = \dfrac{n}{t_m} \]
其中\(n\)为每次读出/写入的字节数,\(t_m\)为存储周期
半导体存储芯片的译码驱动方式
DRAM的刷新
存储器芯片的扩展
Cache
Cache的命中率
在一个程序执行期间,设\(N_c\)为访问Cache的总命中次数,\(N_m\)为访问主存的总次数,则命中率\(h\)(hit rate)为
\[h = \dfrac{N_c}{N_c+N_m} \]
设\(t_c\)为命中时的Cache访问时间,\(t_m\)为未命中时的主存访问时间,通常\(t_m >> tc\) ,\(1-h\)表示未命中率(缺失率,miss rate)
当Cache和主存同时访问时,Cache-主存系统的平均访问时间\(ta\)为:
\[t_a = ht_c + (1-h)t_m \]
当Cache和主存不同时访问时,Cache-主存系统的平均访问时间\(ta\)为(我们一般考虑同时访问的情况):
\[t_a = ht_c+(1-h)(t_m+t_c) = t_c+(1-h)t_m \]
Cache-主存系统的效率
\[e = \dfrac{t_c}{t_a} = \dfrac{\text{访问Cache的时间}}{\text{平均访问时间}}\times 100\% \]
\[= \dfrac{t_c}{t_c+(1-h)\times t_m}\times 100\% \]
Cache-主存系统的加速比
\[S_p = \dfrac{t_m}{t_a} = \dfrac{t_m}{t_c+(1-h)\times t_m} = \dfrac{1}{1-h+\dfrac{1}{r}} \]
其中,\(r=t_m/t_c\)为从主存到Cache速度提升的倍数。
Cache-主存系统的成本
假设计算机中的主存与Cache的容量分别为\(S_1\)和\(S_2\),显然\(S_1 >> S_2\);
主存与Cache的单位价格分别为\(C_1\)和\(C_2\),且\(C_1\)是价格较低的。
那么Cache—主存系统的平均价格\(C\)为
\[C = \dfrac{C_1\times S_1+C_2\times S_2}{S_1+S_2} \]
Cache的映射
替换算法
多级Cache
虚拟存储器
外部存储器
磁盘
非格式化容量
\[\text{非格式化容量} = \text{位密度}\times\dfrac{\text{内圈磁道周长}+\text{外圈磁道周长}}{2}\times\text{每盘面磁道数}\times\text{盘面数} \]
格式化容量
\[\text{格式化容量} = \text{每扇区字节数}\times\text{每道扇区数}\times\text{每盘面磁道数}\times\text{盘面数} \]
平均存取时间
\[\text{平均存取时间} = \text{平均寻道时间}+\text{平均等待时间}+\text{传输时间} \]
数据传输率
\[\text{数据传输率} = \text{每个扇区的字节数}\times\text{每道扇区数}\times\text{磁盘的转速} \]
数据表示
带符号的定点小数
其一般形式为
\[X_s.X_{-1}X_{-2}\cdots X_{-(n-1)} \]
其中第一位是符号位,后面的每一位都在小数点后,也就是说定点小数一定是纯小数,不含整数部分。
原码、反码、补码、移码
原码转换为另外三个码的规则
| 原码符号 | 反码 | 补码 | 移码 |
|---|---|---|---|
| 正 | 相同 | 相同 | 符号位改为1 |
| 负 | 除符号位外取反 | 反码+1 | 符号位与补码相反 |
假设不含符号位有\(n\)位,则原码和反码的范围为\(-2^{n}+1\sim 2^{n}-1\),补码和移码的范围为\(-2^{n}\sim 2^{n}-1\)
以上是定点整数的转换方法,定点小数的转换方法相同,数据范围不同
假设不含符号位有\(n\)位,则原码和反码的范围为\(-(1-2^n)\sim 1-2^n\),补码和移码的范围为\(-1\sim 1-2^n\)
浮点数
浮点数\(N\)由三部分来决定,阶码\(E\),尾数\(M\)和阶码的底\(B\)
\[N = B^E\cdot M \]
阶码的底\(B\)一般隐含表示,取决于机器本身。阶码是定点整数,尾数是定点小数。
非规格化浮点数
非规格化浮点数不要求定点小数的第一位是1.其数据范围如下,假设尾数部分\(n+1\)位,阶码部分\(k+1\)位,均用补码表示
| 阶码最小值 | \(-2^k\) | 阶码最大值 | \(2^k-1\) |
|---|---|---|---|
| 尾数最小负值 | \(-1\) | 尾数最大负值 | \(-2^{-n}\) |
| 尾数最小正值 | \(2^{-n}\) | 尾数最大正值 | \(1-2^{-n}\) |
| 可表示的最小负数 | \(-1\times 2^{2^k-1}\) | 可表示的最大负数 | \(-2^{-n}\times 2^{-2^k}\) |
| 可表示的最小正数 | \(2^{-n}\times 2^{-2^k}\) | 可表示的最大正数 | \((1-2^{-n})\times 2^{2^k-1}\) |
规格化浮点数
要求定点小数的第一位是1.在用补码表示时,符号位和第一位如果不同,则为规格化浮点数。
| 阶码最小值 | \(-2^k\) | 阶码最大值 | \(2^k-1\) |
|---|---|---|---|
| 尾数最小负值 | \(-1\) | 尾数最大负值 | \(-(1/2+2^{-n})\) |
| 尾数最小正值 | \(+1/2\) | 尾数最大正值 | \(1-2^{-n}\) |
| 可表示的最小负数 | \(-1\times 2^{2^k-1}\) | 可表示的最大负数 | \(-(1/2+2^{-n})\times 2^{-2^k}\) |
| 可表示的最小正数 | \(1/2\times 2^{-2^k}\) | 可表示的最大正数 | \((1-2^{-n})\times 2^{2^k-1}\) |
IEEE754标准浮点数
以单精度为例,单精度有32位长,最高位(\(S\))是浮点数的符号位,接下来8位是指数(\(E\)),最后23位是尾数(\(F\))。
其表示为
\[(-1)^S\times (1+F)\times 2^{(E-Bias)} \]
其中,尾数本来应该为1.xxxxx,但是我们将第一位暗含了,所以式子中为\(1+F\),那23位尾数只包含小数点后面的数。这个尾数永远为正,不需要考虑补码等问题,符号由符号位提供。
而\(Bias\)提供了一种类似于移码的方式来表示正负,在单精度中,Bias为\(127\),也就是说,如果我们要表示\(2^6\),则\(E = 6+127 = 133\),而133才是会被记录在那8位尾数中的数字。
单精度表示对象表如下
| 指数 | 尾数 | 表示对象 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 非0 | \(\pm\)非规格化数 |
| 1-254 | 任意 | \(\pm\)浮点数 |
| 255 | 0 | \(\pm\)无穷 |
| 255 | 非0 | NaN |
其中浮点数的表示范围为\(\pm[1,2)\times 2^{[-126,127]}\)
双精度浮点数的Bias为1023。
ASCII码
汉字编码
\[\text{国标码} = (\text{区位码})_{16} + 2020H \]
\[\text{机内码} = (\text{国标码})_{16} + 8080H \]
\[\text{机内码} = (\text{区位码})_{16} + A0A0H \]
Unicode与UTF-8
检错与纠错码
校验码的码距
\[d_{min} \geq t+e+1, 且e\geq t \]
其中\(d_{min}\)为编码码距,\(t\)为可纠错的位数,\(e\)为可检错的位数
\(d_{min}\geq 2\)的数据校验码具有检错的能力
奇偶校验
海明码
设信息码为\(n\)位,欲检测\(1\)位错误,增添\(k\)位校验位,组成\(m=n+k\)位的校验码,应满足
\[2^k\geq n+k+1 \]
CRC码
运算方法与运算器
机器数的逻辑运算
按位与、或、非、异或等等。
机器数的移位运算
算术移位
正数的原码、补码、反码,左移右移都补0.
负数的原码左右都补0;补码右补1,左移补0;反码左右都补1.
运算的结果\(p+q\)位,保留前\(p\)位,常见的舍入方法有:
- 恒舍(切断)。实现简单,误差大。
- 冯诺依曼舍入法,又称恒置1法,把保留部分\(p\)位的最低位置1.实现简单,平均误差接近0,应用较多。
- 下舍上入法,即0舍1入。用\(q\)位的最高位作为标志。如果为0,则全部舍去;如果为1,则在保留的\(p\)位的最低位上加1.
- 查表舍入法,或ROM舍入法。每次经查表来读得相应的处理结果。表的设计通常是当尾数最低\(k-1\)位全1时用截断法,其余用舍入法。实现速度快,虽然增加了硬件,但是整体性能最佳。
逻辑移位
把所有码都看成无符号码,左移右移都添加0,多出来的位直接舍弃。
循环移位
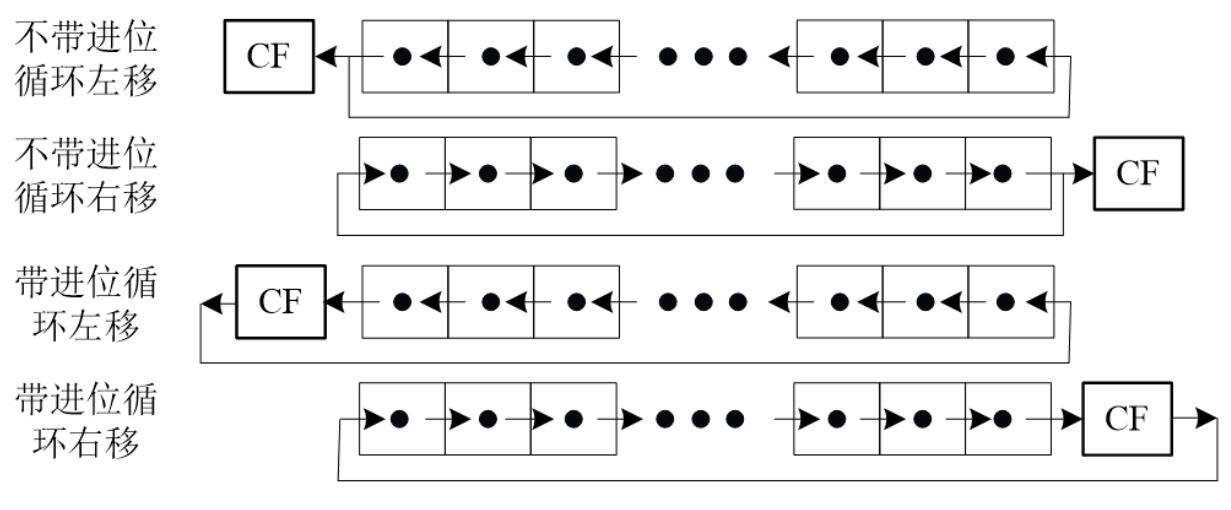
一位全加器
输入\(X_i,Y_i,C_i\),表示两个加数和一个进位。
输出\(Z_i,C_{i+1}\),表示结果和进位。
\[Z_i = X_i\oplus Y_i\oplus C_i \]
\[C_{i+1} = (X_i\cdot Y_i)+(X_i+ Y_i)\cdot C_i \]
若果令\(G_i = X_i\cdot Y_i, P_i = X_i+ Y_i\),则\(C_{i+1}=G_i+P_i\cdot C_i\)
当然\(P_i=X_i\oplus Y_i\)其实是等效的,有些地方会这么写。
\(G_i\)为进位产生函数:若本位两个输入均为\(1\),必向高位产生进位,与低位进位无关。
\(P_i\)为进位传递函数:当\(P_i =1\)时,若低位有进位,本位将产生进位。
n位加减法器
串行(行波)进位的并行加减法器
\(n\)个全加器串接起来,就可以进行两个\(n\)位数的相加减。进位信号是逐级形成的。
并行加法器的快速进位
- 并行进位(先行进位、同时进位、CLA)方式
即把\(C_{i+2}\)用\(C_{i+1}\)表示,把\(C_{i+3}\)用\(C_{i+2}\)表示,以此类推,然后从一开始就得到进位信息。
- 分组并行进位
单级先行进位,即,组内并行,组间串行。因为全部都并行电路很复杂,所以采用这个方法。
多级先行进位,即组内并行,组间并行。
ALU电路
既能完成算术运算又能完成逻辑运算的部件。
定点数加减运算
补码
两个数连同符号位一起相加,符号位产生的进位丢掉。减法则是把右边的加数变成相反数的补码再来相加。得到的结果也是补码。
符号扩展
将采用给定位数表示的数转换成具有更多位数的某种表示形式。
对于补码,正数用0填充,负数用1填充。
溢出判断
有两种情况,一种是正溢,即两个正数相加。一种是负溢,即两个负数相加。
- 采用符号位判断。如果正数相加符号位变成1了,那么正溢。如果负数相加符号位变成0了,那么负溢。
- 采用进位法。如果正数相加,最高有效位产生进位而符号位不产生进位,那么正溢。如果负数相加最高有效位不产生进位,而符号位产生进位,那么负溢。
- 采用变形补码(双符号位补码,模4补码)。计算方法相同,都是相加然后进位。如果符号位为00,则为正数;11则为负数,01则为正溢,10则为负溢。
标志信息
零标志ZF=1表示结果为0,不论有符号还是无符号都有意义。
符号SF表示结果的符号,即最高位。对于无符号数没有意义。
CF表示无符号加减运算时的借进位。加法时CF=1表示溢出,减法时CF=1表示借位。对于有符号数没有意义。
溢出表示OF=1表示有符号数的运算结果发生了溢出。对于无符号数没有意义。
BCD加法器
对于一位数,加出来的结果如果大于9,则加6进位。
移码加减运算
- 两个移码直接相加
- 将结果的符号取反
定点数乘法运算
乘法用加法和移位实现,参照手算竖式乘法。
原码乘法,略。
部分积这个概念可能会考。
- 补码乘法——校正法
计算x*y
当y>0时,不管被乘数x的正负都直接按原码乘法计算,只是移位时按补码规则进行。
y<0时,可以先把[y]补的符号位丢掉不管,仍按原码乘法运算,最后再加上[-x]补进行校正。
综上,表达式为
\[=[X]_补\cdot 0.y_1y_2\cdots y_n + [-X]_补\cdot y_0 \]
- 补码乘法——比较法(Booth法)
我们可以证明,\([-X]_补=-[X]_补\),布斯法从这里入手。
\[[X\cdot Y]_补 = [X]_补\cdot(-y_0\cdot 2^0+y_1\cdot 2^{-1}+y_2\cdot 2^{-2}+\cdots+y_n\cdot 2^{-n}) \]
\[= [X]_补\cdot[-y_0\cdot 2^0+(y_1\cdot 2^{0}-y_1\cdot 2^{-1})+(y_2\cdot 2^{-1}-y_2\cdot 2^{-2})+\cdots+(y_n\cdot 2^{-(n-1)}-y_n\cdot 2^{-n})] \]
\[= [X]_补\cdot[(y_1-y_0)\cdot 2^0+(y_2-y_1)\cdot 2^{-1}+\cdots+(y_n-y_{n-1})\cdot 2^{-(n-1)}+(y_{n+1}-y_n)\cdot 2^{-n}] \]
其中\(y_{n+1}=0\),写出来只是方便起见。
于是我们可以方便的递推
\[[z_0]_补 = 0 \]
\[[z_1]_补 = 2^{-1}\{(y_{n+1}-y_n)[x]_补+[z_0]_补\} \]
\[\vdots \]
\[[z_n]_补=2^{-1}\{(y_2-y_1)[x]_补+[z_{n-1}]_补\} \]
\[[x\cdot y]_补 = [z_n]_补+(y_1-y_0)[x]_补 \]
- 阵列乘法器
原码和补码的乘法算法,利用加法和移位进行,属于串行乘法,它是一行行地来实现竖式乘法的。而阵列乘法器,通过电路实现了整个竖式乘法,速度快。
定点数除法运算
类似的,除法是用减法和移位实现。
原码除法分为恢复余数法和加减交替法
- 恢复余数法是直接作减法试探方法,不管被除数(或余数)减除数是否够减,都一律先做减法。
若余数为正,表示够减,该位商上“1”;若余数为负,表示不够减,该位商上“0”,并要恢复原来的被除数(或余数)。
- 加减交替法
符号位不参与运算;上商 n+1 次;第一次上商判溢出;左移 n 次,加 n+1 或n+2次;用移位的次数判断除法是否结束;若最终余数为负,需恢复余数。
补码除法:补码除法共上商 n +1 次(末位恒置 1)第一次为商符;第一次商可判溢出;加 n+1 次 左移 n 次;用移位的次数判断除法是否结束;精度误差最大为\(2^{-n}\)
浮点数加减运算
步骤如下
- 使两个数的小数点位置对齐
- 将尾数按定点加减运算计算
- 将尾数计算结果重新规格化
- 尾数在规格化后进行舍入
- 判断是否溢出
浮点数乘除运算
步骤如下
- 阶码采用补码(对于IEEE754则不是补码,总之是定点加减)定点加减运算
- 尾数乘除同定点运算
- 规格化
- 舍入
- 溢出判断
运算器的组成和结构
指令系统
存储模式
大端存储(大部分RISC),小端存储(Intel/AMD)
堆栈(Stack):具有先进后出(FILO)操作规则的被特殊定义的主存区域。
使用堆栈时用三个专用地址寄存器来管理
- 堆栈指针(Stack Pointer,SP):指示当前可操作的堆栈单元。
- 堆栈基址(Stack Base,SB):指示堆栈的底部。
- 堆栈界限(Stack Limit,SL):指示堆栈的最顶端
堆栈界限\(=\)堆栈基址\(\pm\)堆栈大小。
寄存器组织
寄存器按功能可以分为通用寄存器和专用寄存器。按可操作性分为可见与不可见寄存器。
典型寄存器有地址寄存器(AR)、数据寄存器(DR)、指令寄存器(IR)、程序计数器(PC)、堆栈指针寄存器(SP)、标志寄存器(FR)等。
指令格式
为了使指令能够有效地指挥计算机完成各种操作,一条指令应包含两个基本要素:操作码和地址码,其基本格式为:操作码字段+地址码字段。
指令功能不同,需要的操作数数量也不同。地址码字段为指令指定源操作数、目的操作数和下条指令地址等信息,格式为:源操作数+目的操作数+下条指令地址。
按照地址码字段的数量,指令可以分为四地址、三地址、两地址、单地址和零地址指令。
- 四地址指令:op,rd, rs1, rs2,ni;
rs1 op rs2->rd, ni提供顺序或转移地址
- 三地址指令:op,rd,rs1,rs2
rs1 op rs2->rd, PC提供顺序地址
- 二地址指令:op,rd,rs1
rd op rs1->rd或rs1 op ACC->rd, PC提供顺序地址
- 单地址指令:op rd
rd op ACC -> ACC或rd自身操作->rd, PC提供顺序地址;或rd提供转移地址。ACC为累加器或操作码隐含指定的操作数。
- 零地址指令:op
由操作码指定操作数(隐含寻址)或无需操作数。
定长操作码
对所有指令的操作码用相同位数的二进制数进行编码,即为定长操作码编码方式。
某计算机的指令系统需要设置\(N\)条指令,若所有指令的操作码均用\(n\)位二进制数表示,则应满足关系式:
\[N\leq 2^n \]
从\(2^n\)个编码中选出\(N\)个编码分配给\(N\)条指令,即可完成操作码设计。
变长操作码
对不同类型的指令操作码用不固定长度的二进制数进行编码即为变长操作码或扩展操作码编码方式。
扩展操作码技术是指令优化技术,其技术核心是:
- 使程序中指令的平均操作码长度尽可能短,以减少操作码在程序中的总位数;
- 尽可能充分地利用指令的二进制数位,以增加指令字表示的操作信息。
扩展操作码的设计原则:
- 如果指令字长固定,则长地址码对应短操作码,操作码长度随地址码长度缩短而增加。
- 如果指令字长可变,则以指令的使用频率作为设计依据,频率高的用短操作码,长的用长操作码。用到了霍夫曼编码。
- 设计总是从短操作码开始,并且保证短码不能是长码的前缀。
寻址
- 隐含寻址:操作数的存放地由操作码指定。
- 立即寻址:操作数在指令中。
- 寄存器寻址:操作数在指令指定的寄存器中。
- 直接寻址:操作数地址在指令中,操作数在主存单元中,访问一次主存便可获得操作数。
- (存储器)间接寻址:操作数地址的地址在指令中,操作数在主存单元中。
- 寄存器间接寻址:操作数地址在指令指定的寄存器中,操作数在主存单元中,访问一次主存即可获得操作数。
- 相对寻址:操作数地址由程序计数器和指令提供的地址偏移量决定,操作数在主存单元中,访问一次主存即可获得操作数。
- 基址寻址:操作数地址由基址寄存器和指令提供的地址偏移量决定,操作数在主存单元中,访问一次主存即可获得操作数。
- 变址寻址:操作数地址由变址寄存器和指令提供的地址偏移量决定,操作数在主存单元中。
- 堆栈寻址:该寻址方式通常由指令操作码指定,用在涉及堆栈操作的指令中,所寻址的操作数在堆栈中。
中央处理器
CPU的功能和结构
CPU的功能
CPU主要由控制器+运算器+寄存器组构成。
CPU具有以下四方面功能
- 指令控制
- 操作控制
- 时间控制
- 数据加工
CPU的主要功能是执行存储在主存中的指令序列,也即执行程序,具体操作如下:
- 取得指令:cpu从主存中取指令,存在指令寄存器中
- 执行指令
- 确定下条指令的地址:可能是顺序地址,或者分支跳转地址
- 重复1~3,直到执行完毕
其中,控制器CU的功能为:从存储器中取指令、对指令译码、产生控制信号并控制计算机系统各部件有序地执行,从而实现这条指令的功能。
控制器组成为:PC,IR,AR,DR,指令译码器,操作控制信号形成部件,时序信号产生器。
指令周期
CPU执行一条指令所用的时间即为指令周期,在指令周期内CPU完成一组操作。
一个周期分为三个子周期:取指令子周期、执行指令子周期(分为取数子周期、执行子周期、存数字周期)、中断子周期。
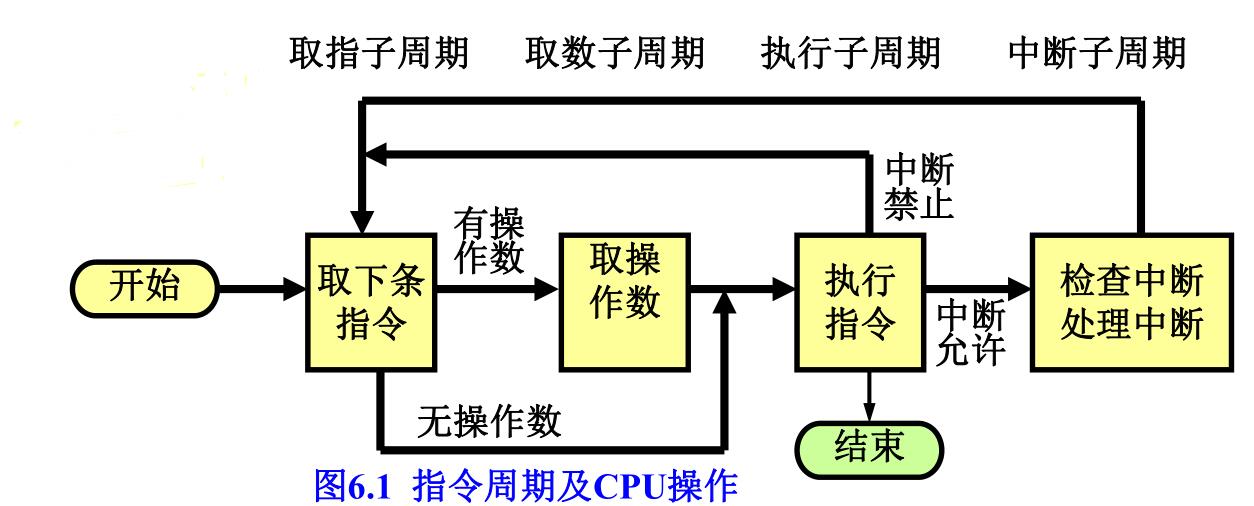
微操作
概念
在CISC系统中,指令周期内的CPU行为常常被分解为一系列微操作\((\mu op)\)
微操作是CPU可以进行的基本或原子操作。它是CPU可实现的、不可分解的操作。以含有一个寄存器传递(移进、移出)操作为标志。
每一个微操作是通过控制器将控制信号发送到相关部件上引起部件动作而完成的。
- 这些控制微操作完成的控制信号称为微命令。
- 微命令是由控制器产生的。
流程
时序信号
CPU执行微操作有严格的时间顺序性,这种时间关系是由计算机的时序系统来控制的。CPU执行微操作序列中的时序信号:
- 指令周期:执行一条指令所用的时间
- CPU周期:完成一个子周期所用的时间
- 节拍周期:完成一个微操作所用的时间
通常利用时序电路为控制器提供所需的时序信号。
- 节拍周期
最基本的时序信号为节拍,它可由顺序脉冲发生器(也称脉冲分配器或节拍脉冲发生器)产生。
节拍周期\(T\):完成各种CPU微操作所需时间的最大者,常作为定义CPU时钟周期\(T_{clk}\)或时钟频率\(f_{clk}\)的依据。
\[T = (1\sim n)\times T_{clk} = (1\sim n)/f_{clk} \]
节拍脉冲发生器分为两类:计数型=计数器+译码器;移位型=移位寄存器+译码器。
- CPU周期(机器周期)
完成一个子周期所用的时间。一般指CPU与内存交换一次信息所需要的时间。若干个节拍组成一个CPU周期。
CPU周期可以设计为定长 CPU周期与不定长CPU周期两种。
- 指令周期
执行一条指令所用的时间。若干个CPU周期组成一个指令周期,指令周期也可以设计为定长指令周期与不定长指令周期两种。
取指令与中断子周期微操作流程
当一条指令在该系统上执行时,可以被看作是一组微操作的执行。
每条指令对应的一组微操作,称为该指令的微操作流程或微操作序列。
- 取指令周期
一个简单的取指令周期可由3个节拍、4个微操作组成
T1: AR<-PC //PC的内容传送到AR
T2: DR<-Memory[AR], Mread //读取主存到DR
PC<-PC+I //PC自增到下一条指令,其中I为指令长度
T3: IR<-DR //DR的内容传送到IR
组合微操作:
T1: AR<-PC
T2: DR<-Memory[AR], Mread
T3: PC<-PC+I
IR<-DR
组合微操作的规则:遵守操作发生的顺序、必须避免冲突
所有指令的取指令操作相同,故取指令周期称为公操作。
- 中断周期
在执行周期结束时有一个检测,用来确定被允许的中断是否已出现,若是,中断周期产生。
中断周期也是公操作。
中断周期微操作序列举例:
T1: DR<-PC //将PC的内容传到DR保护
T2: AR<-Save_Address //中断断点信息保护区的存储单元地址传送到AR
PC<-Routine_Address //中断服务程序首地址送入PC
T3: Memory[AR]<-DR, Mwrite //将老PC的内容保存于主存(如堆栈)中
- 执行周期
- MOV R1, R0
实现将寄存器R0的内容传送至寄存器R1中。
T1: R1<-R0
- MOV R0, X
实现将存储单元X中的内容传送至寄存器R0中。
T1: AR<-IR //IR = X
T2: DR<-Memory[AR], Mread
T3: R0<-DR
- MOV (R1), R0
将寄存器R0的内容传送至由寄存器R1间接寻址的存储单元中。
T1: AR<-R1
T2: DR<-R0
T3: Memory[AR]<-DR, Mwrite
- ADD R1, R0
将寄存器R0的内容与寄存器R1的内容相加并将结果存入R1。
T1: Y<-R0
T2: Z<-R1+Y
T3: R1<-Z
- SUB R0, (X)
实现寄存器R0中的被减数减去存储器地址X间接寻址的存储单元中的减数、将差值传送至寄存器R0中。
T1: AR<-IR //IR = X
T2: DR<-Memory[AR], Mread
T3: AR<-DR
T4: DR<-Memory[AR], Mread
T5: Y<-R0
T6: Z<-Y﹣DR
T7: R0<-Z
- IN R0, P
从I/O地址为P的I/O设备(接口)中输入数据并存入寄存器R0中。
T1: AR<-IR //IR = P
T2: DR<-IO[AR], IOread
T3: R0<-DR
- OUT P, R0
将寄存器R0中的数据输出到I/O地址为P的I/O设备(接口)中。
T1: AR<-IR //IR = P
T2: DR<-R0
T3: IO[AR]<-DR, IOwrite
- JUMP X
无条件跳转指令,实现将程序执行地址从当前跳转指令所在位置转移到存储器地址为X处。
T1: PC<-IR
- JZ offs
采用相对寻址的条件跳转指令。当条件为真(即零标志ZF=1)时,程序发生跳转;条件为假(即零标志ZF=0)时,程序顺序执行下条指令。跳转地址=PC+offs,offs为带符号地址偏移量。
If(ZF==1) then
{
T1: Y<-IR
T2: Z<-PC+Y
T3: PC<-Z
}
- PUSH R0
实现将寄存器R0中的数据压入到堆栈中。
T1: SP<-SP-n // SP指向新栈顶,n为一次压栈的字节数
DR<-R0
T2: AR<-SP
T3: Memory[AR]<-DR, Mwrite
- POP R0
实现将堆栈栈顶的数据弹出至寄存器R0中。
T1: AR<-SP
T2: DR<-Memory[AR], Mread
T3: R0<-DR
SP<-SP+n //将SP指向新栈顶,n为一次弹出的字节数
- CALL(X)
子程序调用指令。将程序执行地址从当前调用指令所在位置转移到以存储器地址X间接寻址的存储单元处,并保存返回地址。
T1:SP<-SP-n
DR<-PC
T2:AR<-SP
T3:Memory[AR]<-DR, Mwrite
T4:AR<-IR
T5:DR<-Memory[AR], Mread
T6:PC<-DR
- RET
子程序返回指令,实现从堆栈栈顶处获得子程序调用时保存的返回主程序的地址。
T1: AR<-SP
T2: DR<-Memory[AR], Mread
T3: PC<-DR
SP<-SP+n
控制器的组成
控制器应完成的任务:
- 产生微命令(即控制信号)
- 按节拍产生微命令
在设计控制器前需要:
- 定义计算机基本硬件组成和基本指令系统
- 基于定义的硬件结构,针对每条指令,描述CPU完成的微操作
- 确定控制单元应该完成的功能,即何时产生何种微命令
有两种方法:
- 硬布线控制设计法
- 微程序控制或微码控制设计法
硬布线控制器设计
硬布线控制器设计法将控制单元看作一个顺序逻辑电路或有限状态机,它可以产生规定顺序的控制信号,这些信号与提供给控制单元的指令相对应。
它的设计目标是:使用最少的元器件,达到最快的操作速度。
RISC-V
对于RISC-V,其为单周期实现。
类x86
对于类x86系统,其为多周期实现。有两种设计方法:
- 采用一级时序,即只利用节拍信号。一条指令执行的全过程是用一个从取指令到执行指令的完整微操作序列来描述的,而且对这个微操作序列也是从头至尾分配节拍的。
- 采用两级时序,即利用节拍和CPU周期两种时间信号。按照CPU周期来描述一条指令的微操作序列。
我们要从微操作序列得出微命令序列。例如把AR<-PC转换为\(PC_{out},AR_{in}\)
由控制单元产生并加载到CPU内外的全部控制信号均可用下述形式表述:
两级时序:
\[C_i = \sum(M_m\cdot T_n\cdot I_j\cdot F_k) \]
在执行指令\(I_j\)时,若状态\(F_k\)满足要求,则在第\(m\)个CPU周期\(M_m\)的第\(n\)个节拍\(T_n\),控制单元发出\(C_i\)控制命令。
一级时序:
\[C_i = \sum(T_n\cdot I_j\cdot F_k) \]
总结:
- 每个控制信号的逻辑表达式就是一个与或逻辑方程式。
- 用一个与或逻辑电路就可以实现该控制信号的生成。
- 将所有控制信号的与或逻辑电路组合在一起就构成了硬布线控制单元。
- 时间信息(单周期实现不需要)、指令信息、状态信息是硬布线控制单元的输入,控制信号是硬布线控制单元的输出。
- 特点:
- 一旦完成设计,改变控制器的行为的唯一方法就是重新设计电路(修改不灵活)
- 在现代复杂处理器中,需要定义庞大的方程组(与或组合电路实现困难)
微程序控制器设计
用软件方法组织和控制数据处理系统的信息传送,并最终用硬件实现。依据微程序顺序产生一条指令执行时所需的全部控制信号。相当于把控制信号存储起来,因此又称存储控制逻辑方法。
对在一个时间单位(节拍)内出现的一组微操作进行描述的语句称作微指令。
一个微指令序列称作微程序或固件。
通过一组微指令产生的控制信号,使一条指令中的所有微操作得以实现,从而实现一条指令的功能。
一条(机器)指令对应一个微程序,该微程序包含从取指令到执行指令一个完整微操作序列对应的全部微指令,它被存入一个称为控制存储器的ROM中。
微指令周期:一条微指令执行的时间(包括从控制存储器中取得微指令和执行微指令所用时间)。
微指令格式
水平型微指令
多个控制信号同时有效->多个微操作同时发生
垂直型微指令
类似于机器指令,利用微操作码的不同编码来表示不同的微操作功能。

微程序控制器的一般结构和工作原理
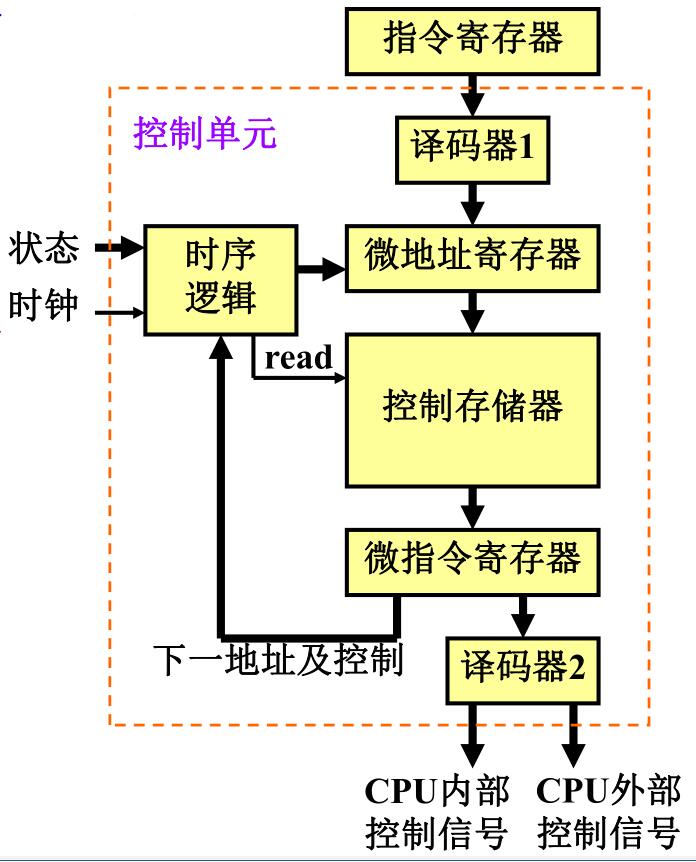
微指令地址的生成
- 两地址格式
- 单地址格式
- 可变格式
微指令控制域编码
- 水平型微指令控制域的编码:
- 直接表示法
- 译码法
- 字段译码法
- 垂直型微指令控制域的编码
微程序设计及示例
微程序结构
在设计微程序时,通常采用如下两种典型结构
- 一条指令对应一段完整的微程序
- 将微程序中的公共部分设计成微子程序进行公共调用
编写微程序
CPU性能测量与提高
CPU性能测量
CPU主频\(f_{CLK}\):CPU使用的时钟的频率,单位为赫兹。
CPU时钟周期\(T_{CLK}\):时钟频率的倒数。
一般而言,主频高代表速度快。
CPU时间
运行一个程序所花费的时间
响应时间:CPU时间与等待时间(包括用于磁盘访问、存储器访问、I/O操作、操作系统开销等时间)的总和。
假设时钟周期为\(T_{CLK}\),执行某程序时,CPU需要使用\(N\)个时钟周期,那么,CPU执行该程序所用时间为
\[T_{CPU}=N\times T_{CLK} = N/f_{CLK} \]
CPI与IPC
CPI是每条指令执行所用的时钟数的平均值。
IPC是每时钟周期执行的指令数。
设某个程序要用\(N\)个时钟周期,该程序汇总的指令数为\(I\),其CPI记为\(CPI\),则
\[N = I\times CPI \]
\[T_{CPU} = I\times CPI\times T_{CLK} = \dfrac{I\times CPI}{f_{CLK}} \]
有三方面的因素使得程序的CPI可能不同于CPU执行的CPI:
- Cache行为发生变化
- 指令混合发生变化
- 分支预测发生变化
影响CPU性能的三个关键因素:
- CPI
- 时钟频率
- 指令数
MIPS
CPU每秒钟执行的百万指令数。
\[MIPS = \dfrac{I}{T\times 10^6} = \dfrac{f_{CLK}}{CPI\times 10^6} \]
其中\(T\)为程序的执行时间。
MIPS的局限:
- 不能对指令集不同的计算机使用MIPS进行比较:MIPS只说明了指令执行速率,而没有考虑指令的能力
- 计算机对所有程序没有单一的MIPS值:对于同一个计算机上的不同程序,MIPS是变化的
- MIPS会与性能反向变化
Flops
CPU每秒完成的浮点运算次数
\[FLOPS = \dfrac{M}{T} \]
其中\(M\)为浮点运算次数,\(T\)为执行时间。
FLOPS可以用于不同计算机之间的比较。
就像MB,GB,TB。FLOPS也有MFLOPS,GFLOPS,PFLOPS等等
CPU性能提高
- 采用更先进的硅加工制造技术
- 缩短指令执行路径长度。减少执行指令的时钟周期数:优化微操作、微程序;双总线、三总线;增加特定硬件,实现并行
- 简化组织结构来缩短时钟周期。例如RISC
- 采用并行处理技术。指令级和处理器级并行
多核与多线程技术
流水线技术
流水线处理的概念
流水线的处理方式
若将一重复的处理过程分解为若干子过程,每个子过程都可在专用设备构成的流水线功能段上实现,并可与其它子过程同时执行,这种技术称为流水技术。
流水线的类型
按流水线位于计算机系统的层次划分
- 系统级流水线/宏流水线:在多个系统中有多个处理机串行构成的流水线
- 处理器级流水线:在处理器内部由多个部件构成的流水线。——指令流水线
- 部件级流水线:在处理器中某部件内部由多个子部件构成的流水线。
按功能强弱划分
- 单功能流水线
- 多功能流水线
按是否有反馈回路划分
- 线性流水线
- 非线性流水线-流水线调度
按流水线输出端任务流出顺序与输入端任务流入顺序是否相同划分
- 顺序流动流水线(入出顺序相同)
- 异步流动流水线(入出顺序不同)
按流水线一次处理对象的数量划分
- 标量流水线
- 超标量流水线
- 向量流水线
- 超长指令字流水线
设计运算流水线的一般方法
- 寻找一个适当的、可分解为多步骤的、连续运行的算法,该算法的每一步骤应是时间均衡的、可以由硬件电路实现的。
- 将实现算法每一步骤的硬件电路作为流水线的一段,并按照步骤顺序将各段连接起来。
- 在流水线各段之间放置快速缓冲寄存器来分离各段,并利用缓冲寄存器逐段传送处理数据(部分或全部结果)。所有缓冲寄存器受同一时钟控制。
指令流水线
基本的指令流水线
指令流水线是利用执行指令时存在的直接并行性实现多条指令重叠执行的一种技术。
指令流水线对于程序员是不可见的,它由程序编译器和CPU内部程序控制单元自动管理。
如果流水线各段采用同步方式控制各段间信息的同步推进,则流水线同步控制时钟的周期应选定为
\[T_{CLK} = \max_i\{\tau_i\} \]
其中\(\tau_i\)是该指令的运行时间。由于时钟周期取决于最长指令的运行时间,所以其他指令运行完后就要等待,造成浪费,速度减慢。所以要将指令的执行步骤再分解,使每一步骤所用时间尽可能均衡,并依此设计一个多级的指令流水线。
例如,将指令处理分为以下四步
- 指令获取(IF):从主存或cache中获取指令并对指令进行译码
- 操作数加载(OL):从主存或cache中获取操作数放入寄存器中
- 执行指令(EX):利用ALU等执行部件,对寄存器中的操作数进行处理,结果存于寄存器中
- 写操作数(WO、OS):将寄存器中的结果存入主存或cache中
指令流水线策略
- 采用深度指令流水线结构
将指令的执行过程进一步细化,使流水线的级(段)数变多,而每一级的工作更少(有可能一个时钟周期完成)、时间更均衡。
- 多条流水线结构
流水线性能测量
时空图
装入时间=(流水线级数-1)\(\times\)时钟周期\(\tau\);\(\tau=(1\sim n)\times T_{CLK}\)
吞吐率
吞吐率:指单位时间内流水线所完成的任务数或输出结果的数量,它是衡量流水线速度的重要指标。
最大吞吐率\(TP_{max}\):流水线在达到稳定状态后所得到的吞吐率。
假设流水线各段运行时间相等,为\(1\)个时钟周期\(T_{CLK}\),则:
\[TP_{max} = 1/T_{CLK} \]
假设流水线各段运行时间不等,第\(i\)段时间为\(\tau_i\),则:
\[TP_{max} = 1/\max_i\{\tau_i\} \]
所以瓶颈在于最慢的一段。消除瓶颈的办法有:
- 细分瓶颈段(首选)(例如把他拆分成两个阶段)
- 重复设置瓶颈段(即物理上再增加一个一样的,和原来的并联)
实际吞吐率
之前说的吞吐率是当待执行任务无限多时,取得的极限。若流水线由m段组成,完成n个任务的吞吐率称为实际吞吐率,记作\(TP\)。
假设流水线各段运行时间相等,为\(1\)个时钟周期\(T_{CLK}\),在不出现流水线断流的情况下,完成\(n\)个任务所用时间为
\[T_n(m) = (m+(n-1))\tau = (m+(n-1))T_{CLK} \]
实际吞吐率为
\[TP = \dfrac{n}{T_n(m)} = \dfrac{n}{(m+(n-1))\times T_{CLK}} = \dfrac{TP_{max}}{1+\dfrac{m-1}{n}} \]
假设流水线各段运行时间不等,第\(i\)段时间为\(\tau_i\) ,则完成\(n\)个任务所用时间为
\[T_n(m) = \sum^m_{i=1}\tau_i + (n-1)\times \max_i\{\tau_i\} \]
实际吞吐率为
\[TP = \dfrac{n}{\sum^m_{i=1}\tau_i + (n-1)\times \max_i\{\tau_i\}} \]
对于指令流水线而言,吞吐率TP就是每秒执行的指令数,所以也可以用MIPS指标表示吞吐率,即
\[TP = MIPS = f_{CLK}/CPI \]
对于单流水线系统,它的\(CPI\)是\(1\),所以\(TP_{max} = f_{CLK}\)
加速比
若流水线为\(m\)段,加速比\(S\)定义为等功能的非流水线执行时间\(T(1)\)与流水线执行时间\(T(m)\)之比,即
\[S = S_n(m) = T_n(1)/T_n(m) \]
若每段运行时间均为\(\tau\),在不流水情况下,总时间为\(T_n(1)=nm\tau\)
在流水但不出现断流的情况下,完成n个任务所需时间为\(T_n(m)=m\tau+(n-1)\tau\),因此
\[S_n(m) = \dfrac{mn}{m+n-1} = \dfrac{m}{1+\dfrac{m-1}{n}} \]
从上式可以看出,增大流水线的级数和送入流水线的指令数均可以加速流水线的运行速度。
效率
效率:流水线中各功能段(或设备)的利用率。
由于流水线有通过(填充)时间和排空时间,还有各种引起断流的状况,所以流水线的各段并非一直满负荷工作,效率\(E<1\)。
通常用流水线各段处于工作时间的时空区(面积)与流水线中各段总的时空区(面积)之比来衡量流水线的效率。
\[E = \dfrac{n个任务占用的时空区}{m个段总的时空区} \]
假设流水线各段运行时间相等为\(\tau\),则整个流水线效率\(e\)为:
\[E = \dfrac{mn\tau}{m(m+n-1)\tau} = \dfrac{n}{m+n-1} = \dfrac{1}{1+\dfrac{m-1}{n}} \]
指令流水线的性能提高
流水线的基本性能问题
限制指令流水线性能提高的因素:
- 流水线的深度受限于流水线的延迟、流水线段的时间不均衡和流水线的额外开销。
- 指令执行时可能存在的“相关”或“冒险”问题。
冒险:指相邻或相近的两条指令因存在某种关联,后一条指令不能在原指定的时钟周期开始执行。
冒险分为三类:
- 结构冒险:资源冲突
- 数据冒险:一条指令需要用到前面某条指令的结果
- 控制冒险:分支等转移类指令/其他能够改变PC值的指令
前两个是局部性相关,后一个是全局性相关
结构冒险
有两种情况会导致结构冒险:
部分功能单元没有充分流水
解决办法:将流水线设计的更合理。
资源冲突
当两个以上流水线段需要同时使用同一个硬件资源时,发生冲突。
解决办法:
- 增加资源副本。如哈佛结构、两个ALU
- 改变资源以便它们能并发的使用。不相关的数据尽量使用不同的寄存器;寄存器重命名
- 通过延迟(或暂停)流水线的冲突段或在冲突段插入流水线气泡(气泡在流水线中只占资源不做实际操作),使各段“轮流”使用资源。
数据冒险
指令在流水线中重叠执行有可能改变指令读/写操作数的顺序
当一条指令的结果还未有效生成,该结果就被作为后续指令的操作数时,数据冒险出现。
解决办法:
- 增加专用硬件(推后法)。增加流水线互锁(pipeline interlock)硬件。当互锁硬件发现数据相关时,使流水线工作停顿下来,直到冒险消失为止。
- 采用直通/转发技术
- 乱序,流水线(指令)调度:利用编译器(RISC),硬件(CISC)。编译器可以对指令重新排序或插入空操作指令
- 对寄存器读写做特别设计
控制冒险
使程序执行顺序发生改变的转移指令有两类:
- 无条件转移指令(如无条件跳转、调用、返回指令等)
- 条件分支转移指令(为零跳转、循环控制指令等)
处理办法:
- 冻结流水线
- 静态分支预测
- 动态分支预测
- 延迟分支
冒险影响性能
冒险可能引起流水线停顿, 停顿也称为流水线气泡。
有停顿的流水线的CPI为:CPI = 理想流水线CPI+(结构冒险停顿 + 数据冒险停顿 + 控制冒险停顿) / 指令数
有停顿的流水线的加速比为:
\[加速比=\dfrac{流水线深度}{1+平均每条指令的流水线停顿周期} \]
多发射处理器
多发射(Multiple Issue)是在一个时钟周期内启动多个指令并行执行的处理器实现方案。
实现多发射处理器主要有两种方法:
- 静态多发射——编译时由编译器决定
- 动态多发射——执行过程中由处理器决定